在近期的一次科技讨论热潮中,关于人工智能领域中的Scaling Law再次成为焦点。这一讨论紧随Ilya关于“预训练时代或将落幕”的言论之后,引起了业界的广泛关注。
在备受瞩目的NeurIPS会议上,OpenAI的杰出成员Noam Brown发表了自己的见解。这位曾在meta任职,并因开发出首个在战略游戏中达到人类水平的AI而闻名的科学家,如今在OpenAI专注于多步推理、自我博弈及多智能体AI的研究。他在此次演讲中,提出了一个全新的视角,认为o1代表了一种以推理计算为核心的全新Scaling方式。

据与会者分享,Noam Brown首先回顾了Scaling Law的历史演进。他指出,从2019年的GPT-2到如今的GPT-4,AI取得的惊人进步主要得益于数据和算力规模的扩大。然而,即便如此,大语言模型在处理如井字棋这样的简单问题时仍显得力不从心。

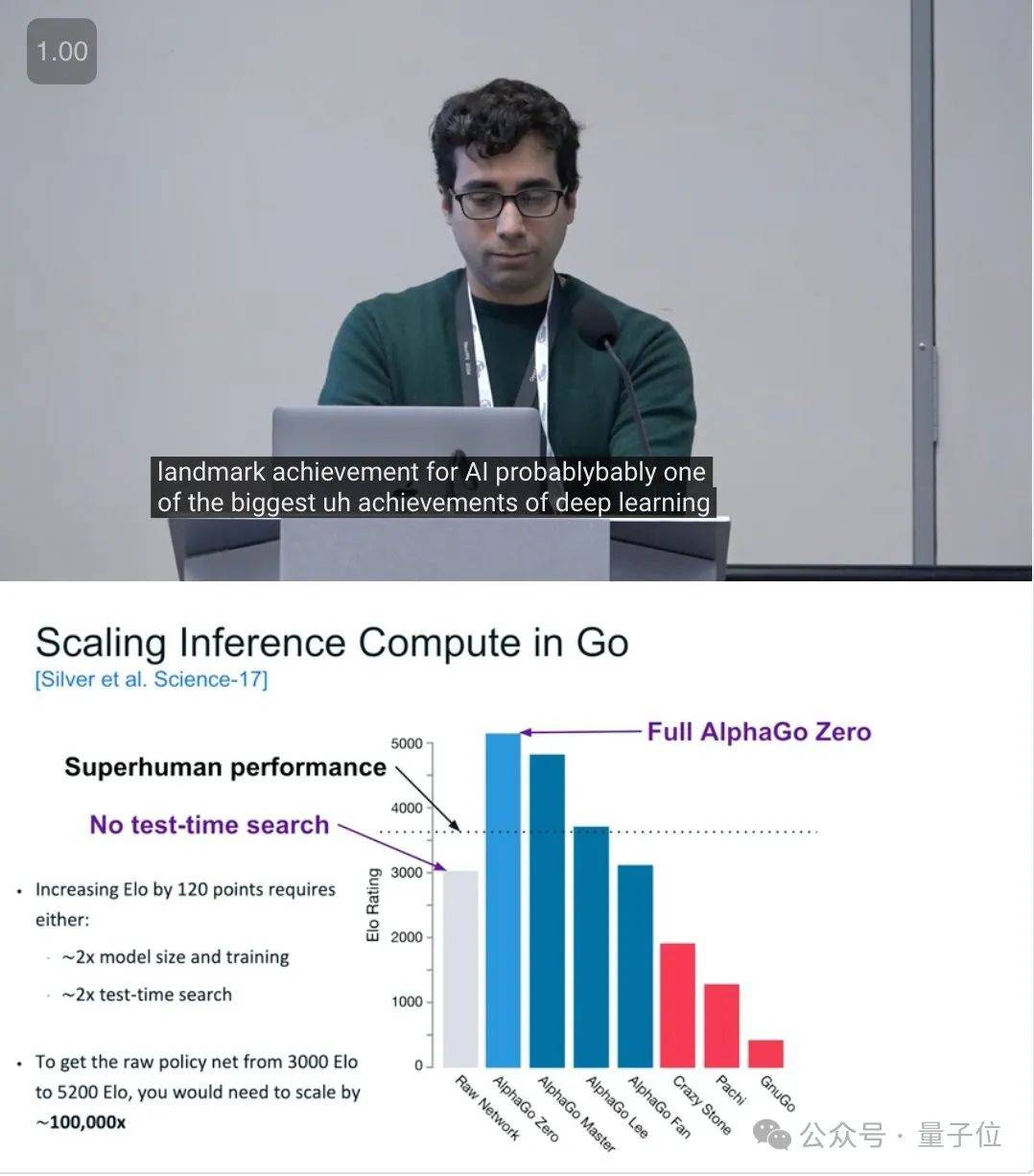
这一现状引发了Noam Brown的深思:我们是否还需要继续投入高昂的成本来训练更好的AI?他提出,推理的成本在过去被严重低估,而o1则为Scaling带来了一个新的维度。他进一步追溯了历史上模型展现出的类似规律,并提到了棋牌游戏中推理的扩展,从backgammon到国际象棋再到围棋,AlphaGo Zero在原始神经网络基础上实现的Elo评分大幅提升,正是得益于测试时间搜索(test-time search)的引入。
Noam Brown还引用了Andy L.Jones关于游戏Scaling Laws的图表,指出可以用10倍的预训练计算量换取15倍的测试时间计算量。他推测,如果将这一规律扩展到语言模型(LLMs)上,或许也能得到类似的结果。同时,他也透露了o1未来将具备更高的推理计算能力,并认为LLM的概念不应仅限于聊天机器人,而应有更广阔的发展空间。
然而,Noam Brown的观点并非毫无争议。有从业者指出,推理时间计算(Inference Time Computation)并非新鲜事物,且在一些游戏中,推理时间计算一开始就备受关注,但后来随着离线学习策略的发展,大量在线计算时间被节省下来。因此,减少面向用户的推理时间计算是一个深思熟虑的选择,这一趋势在LLMs中也得到了延续。

此次讨论原本是关于数学AI的研讨会,但Noam Brown的演讲却意外地将话题引向了大模型推理Scaling Law的讨论。现场人头攒动,据说还有不少人因房间太小而在门口排队等待。
此次讨论不仅展示了业界对于Scaling Law的持续关注,也反映了AI领域在不断探索新的发展方向和突破点。未来,随着技术的不断进步和应用的不断拓展,AI领域或将迎来更多令人瞩目的创新和变革。







