在人工智能领域,当AI模型的记忆力达到千万级Token的惊人水平时,如何准确衡量它们的真实能力成为了一个关键问题。OpenAI近期提出的MRCR基准测试,为这一难题提供了新的解答。这一测试不再局限于简单的信息检索,而是要求AI模型在浩瀚的文本数据中,精确识别并定位出多个完全相同的特定信息,其难度被形象地比喻为“AI界的奥运会”。
正如雕塑家米开朗基罗所言:“雕塑在大理石块中已经完成,我只需要凿去多余的材料。”AI在处理超长上下文时,也需具备这种剔除无关信息、揭示本质的能力。一个超长的上下文,对于AI而言,就如同米开朗基罗手中的大理石块,需要精心雕琢,方能显现出内在的价值。

回想起GPT-4时代,Greg Kamradt提出的“大海捞针”测试,旨在评估AI模型在超长文本中检索特定信息的能力。然而,随着AI技术的飞速发展,这一测试标准已显得力不从心。OpenAI最新发布的o3和o4-mini模型,更是让操纵AI聊天界面的复杂度大幅提升,堪比驾驶宇宙飞船。
在此背景下,OpenAI推出了MRCR基准测试,旨在更全面地评估AI模型的上下文处理能力。如果说“大海捞针”测试是要求AI从海量信息中找出一根特定的“针”,那么MRCR测试则是要求AI在多个一模一样的“针”中,准确识别并定位出特定的几根,其难度之大,可见一斑。
在MRCR测试中,AI模型需要面对的挑战不仅仅是信息检索,更包括在极端干扰下保持精确性和鲁棒性。OpenAI提供的一个测试案例显示,模型需要在一段长对话中,准确识别并修改第二首关于“tapirs”的诗的开头部分。这一测试不仅考验了模型的记忆力,更考验了其理解和区分复杂上下文的能力。

值得注意的是,在MRCR测试中,模型的准确性随着上下文长度的增加和干扰项的增多而迅速降低。即使在GPT4.1这样的顶级模型中,也未能完全避免这一趋势。这表明,在处理超长上下文时,即使是最先进的AI模型也面临着巨大的挑战。
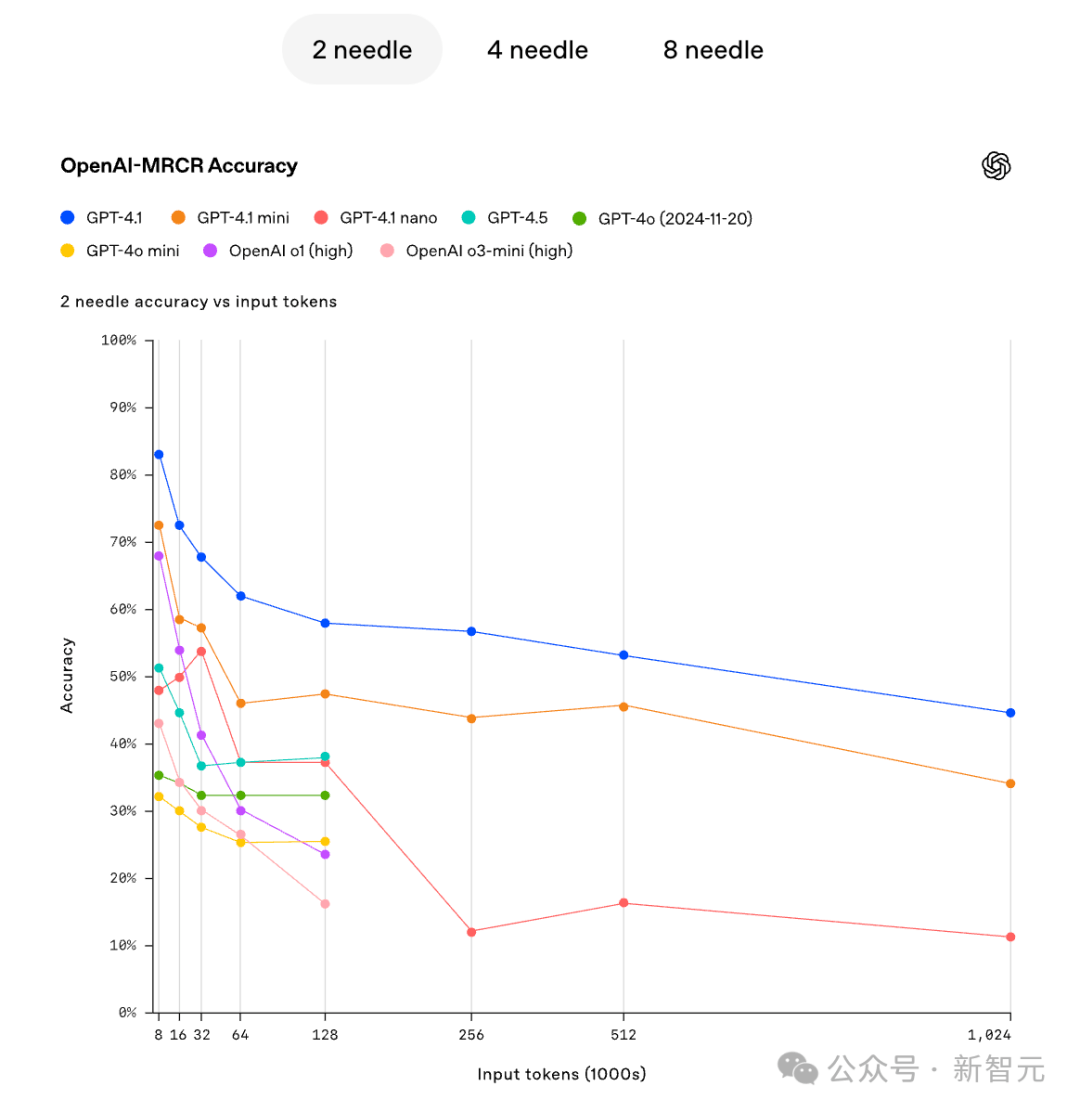
MRCR测试还揭示了一个有趣的现象:在处理复杂任务时,并不是模型越大越好。在某些情况下,较小的模型甚至能够表现出更好的性能。这提示我们,在开发AI模型时,除了追求规模上的提升外,还需要注重模型的结构和优化。
随着AI技术的不断发展,基准测试也在不断更新和完善。从简单的问答到复杂的推理任务,从基础的语言理解到极限的“大海捞针”再到更严格的MRCR测试,AI大模型的基准测试就像是一场永无止境的“考试”。这些测试不仅揭示了当前AI的能力边界,更推动了技术的进步和模型的发展。
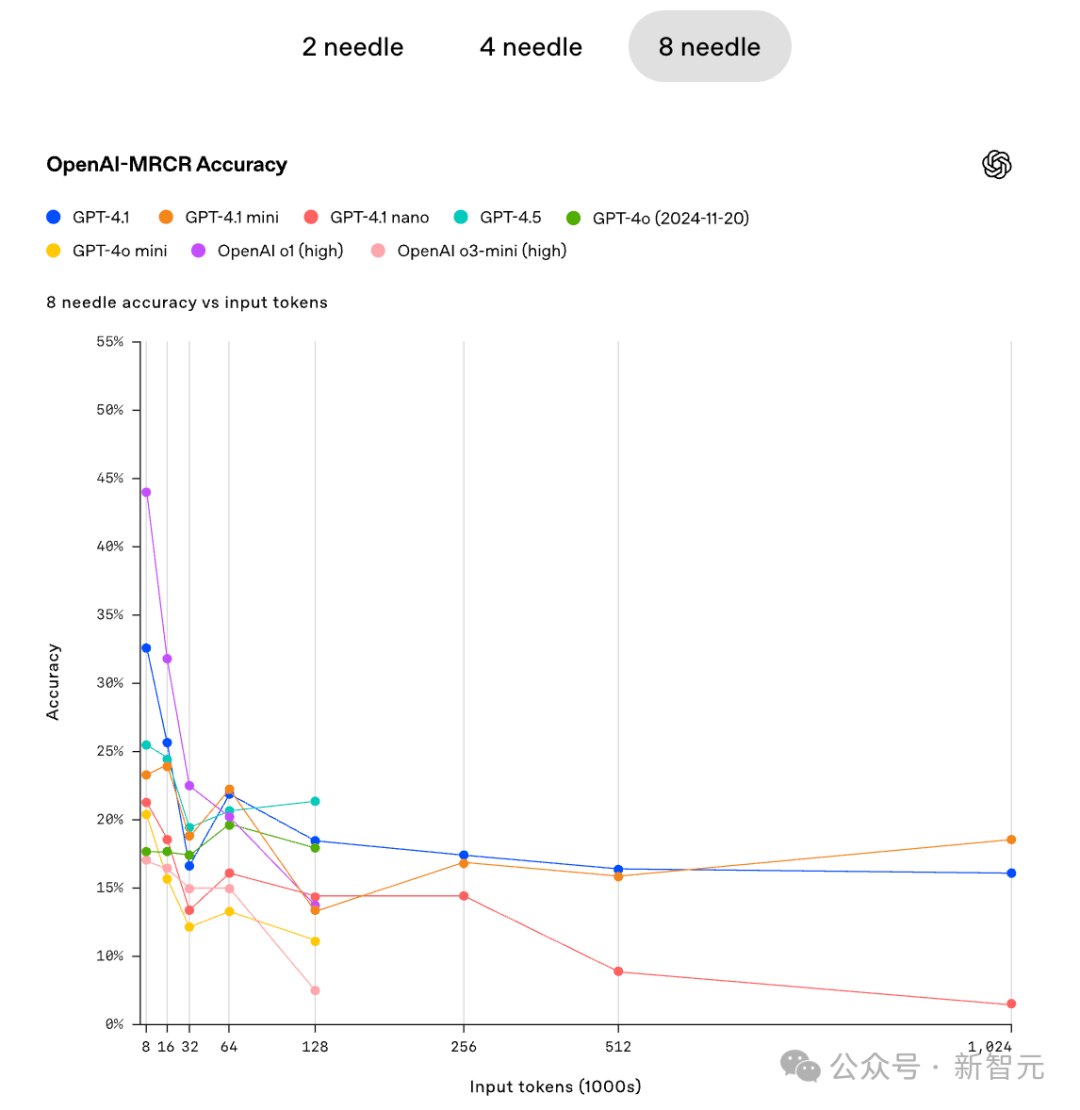
总之,MRCR基准测试的推出标志着AI领域又向前迈进了一步。它不仅为评估AI模型的真正实力提供了新的标准和方法,更为推动下一代更强大、更可靠的AI模型的诞生奠定了坚实的基础。









