在科技巨头OpenAI宣布将连续12天发布更新的前夕,谷歌于12月11日深夜悄然推出了其新一代模型——Gemini 2.0。这一举动似乎是对OpenAI近期一系列发布动作的巧妙回击。
Gemini 2.0的发布标志着谷歌在AI领域的又一次重大突破,特别是针对Agent功能的强化。Agent功能,即智能体功能,使AI能够感知环境、执行任务,并在一定程度上自主做出决策,从而更加自动化地完成各种任务。
与OpenAI的发布内容相比,谷歌此次显得更为慷慨。OpenAI在凌晨两点的更新中,主要宣布了与Apple Intelligence的合作,这一合作被普遍期待能与Agent功能紧密相关。而谷歌则一次性发布了四个与Agent相关的功能,包括:
Project Astra,它允许用户在Gemini应用中直接调用Google Lens和地图功能,以解决各种实际问题。
Project Mariner,这是一个Chrome浏览器的实验性功能,用户可以通过简单的提示词,让AI代理在浏览器中浏览网页并完成各种任务。
Jules,一个可以嵌入GitHub的编程Agent。用户只需用自然语言描述问题,Jules就能生成可以直接合并到GitHub项目中的代码。

以及一个游戏Agent,它能够实时解读屏幕画面,在玩家打游戏时通过语音交流提供AI打法提示。
值得注意的是,Gemini 2.0 Flash及其API目前可免费使用,用户可以通过Google AI Studio和Vertex AI中的Gemini API进行访问,每分钟最多可提问15次,每天最多1500次,预计明年初将全面开放。
Gemini 2.0 Flash作为2.0家族的首个模型,不仅主推原生多模态输入输出和Agent功能,而且速度比1.5 Pro快两倍,关键性能指标甚至超越了1.5 Pro。它还支持原生工具调用、实时音视频流输入等新功能。
Gemini 2.0在多模态、文本、代码、视频、空间理解和推理能力等方面都实现了全面提升。例如,在空间理解方面,利用Spatial Understanding功能,用户可以上传一张图片,Gemini将快速进行物体检测和标注,并生成结构化的数据(JSON格式)。这一功能可能广泛应用于机器学习训练数据准备、图像分析或计算机视觉研究等领域。
Gemini 2.0还支持全新的输出模态,包括文本、音频和图像的集成响应,多语言原生音频输出(8种高品质语音),以及原生图像输出。用户还可以进行多轮编辑迭代,直到生成满意的图像。
在原生工具使用方面,Gemini 2.0可以直接调用Google搜索、代码执行等工具,还能通过函数调用使用自定义的第三方函数。多模态实时API则支持实时音视频流输入,进行语音活动检测,并能集成多个工具完成复杂任务。
谷歌正在积极探索AI“代理”的应用,旨在打造能够自主理解、规划和执行任务的智能助手。他们已推出了一系列Agent原型(目前仅供测试人员使用),展示了AI代理在不同领域的巨大潜力。
例如,Jules可以作为AI编程伙伴,帮助开发者处理Python和Java的编码任务,与GitHub工作流无缝集成,高效地修改多个文件,甚至准备pull requests。Colab数据科学代理则可以帮助用户完成繁琐的数据分析工作,只需用自然语言描述分析目标,Colab就能自动生成一个完整的notebook,并在几分钟内提供洞察。
Project Mariner则致力于探索人机交互的未来,从浏览器开始。它是一个实验性的Chrome扩展程序,可以让AI代理在浏览器中执行各种任务,如查找信息、填写表格等。
在游戏领域,谷歌也利用DeepMind在游戏AI方面的丰富经验,将Gemini 2.0应用于游戏代理的开发。这些代理不仅能陪伴玩家一起玩游戏,还能提供专业的指导,并连接到Google搜索,获取海量的游戏知识。
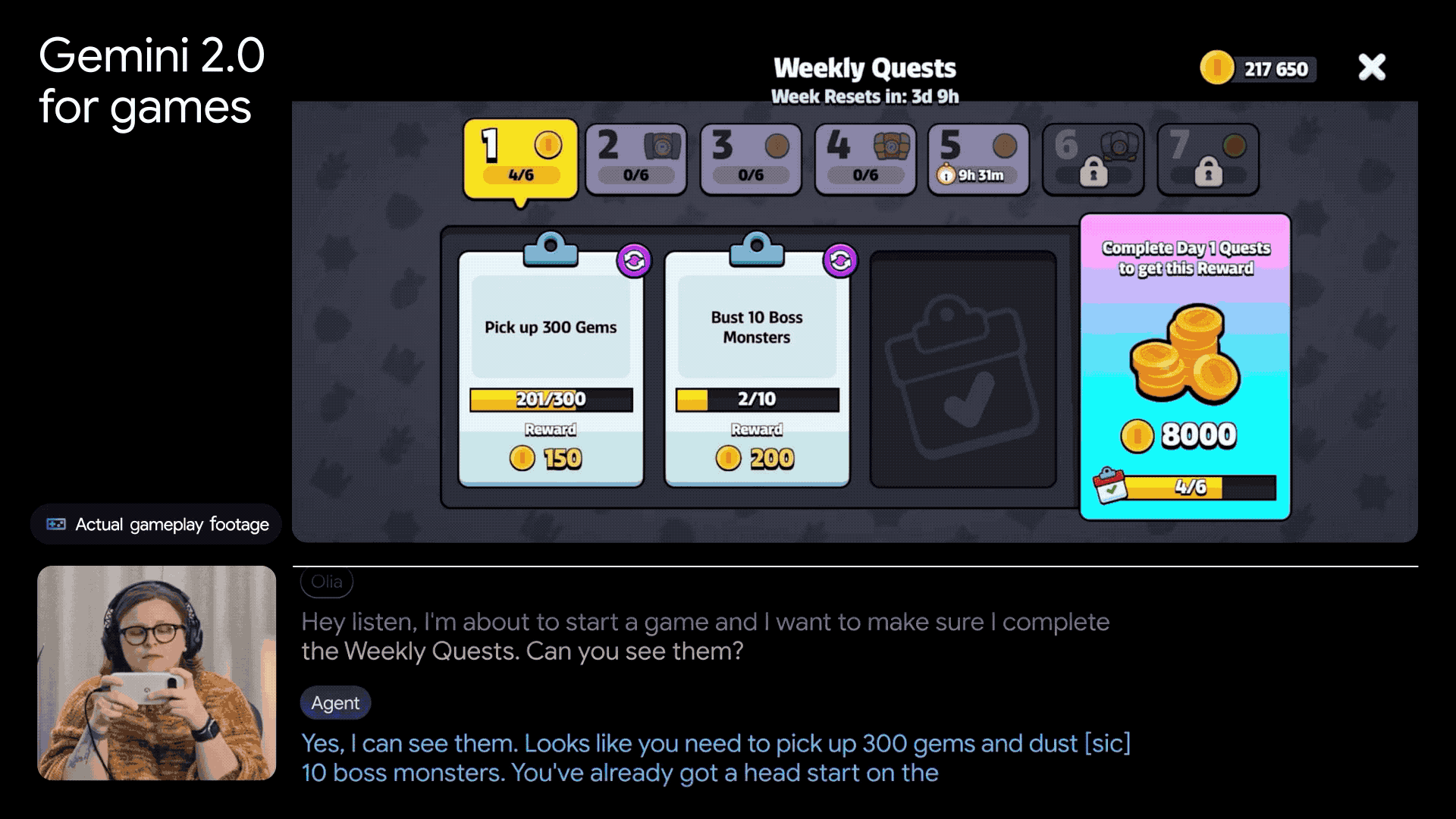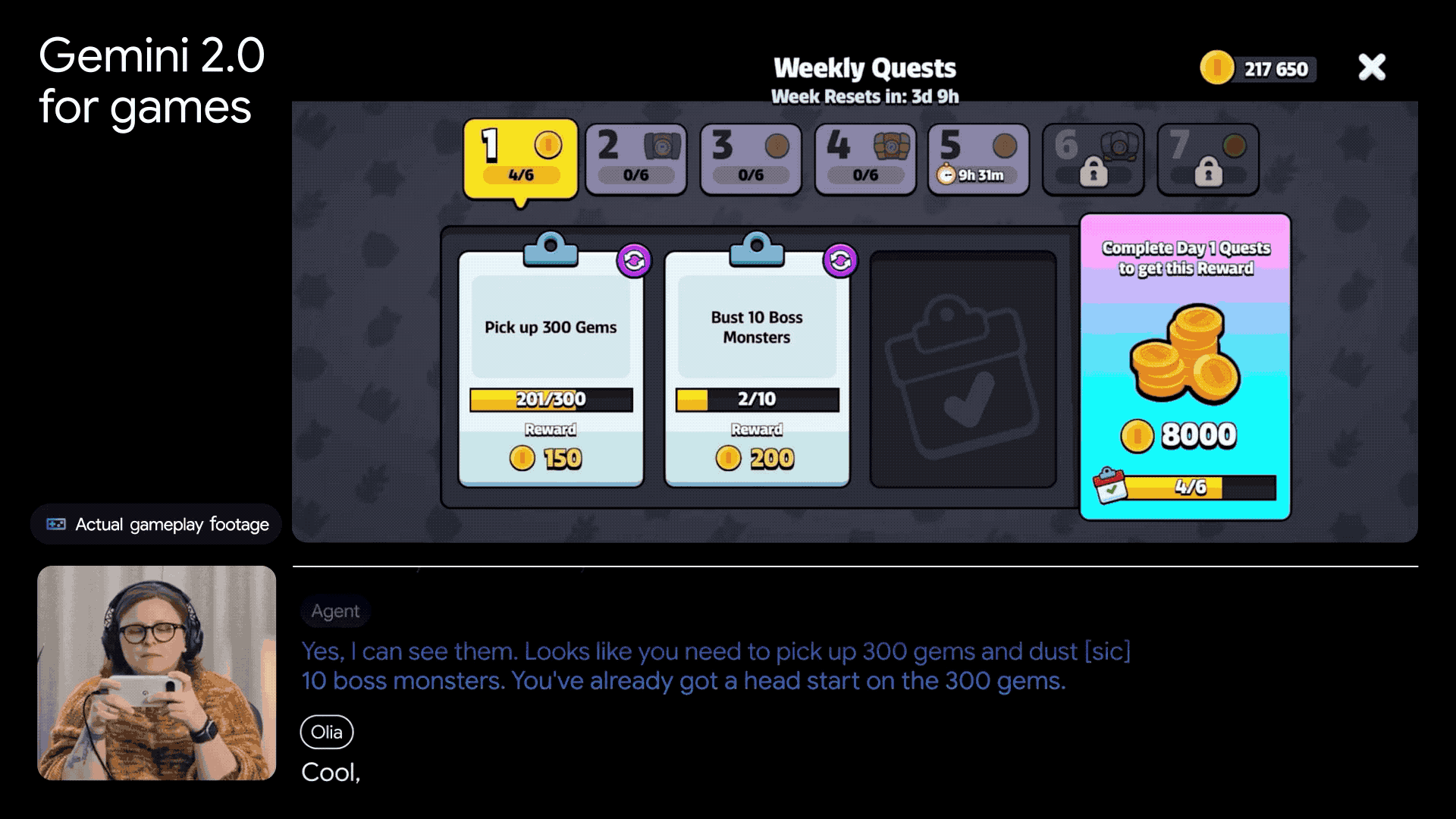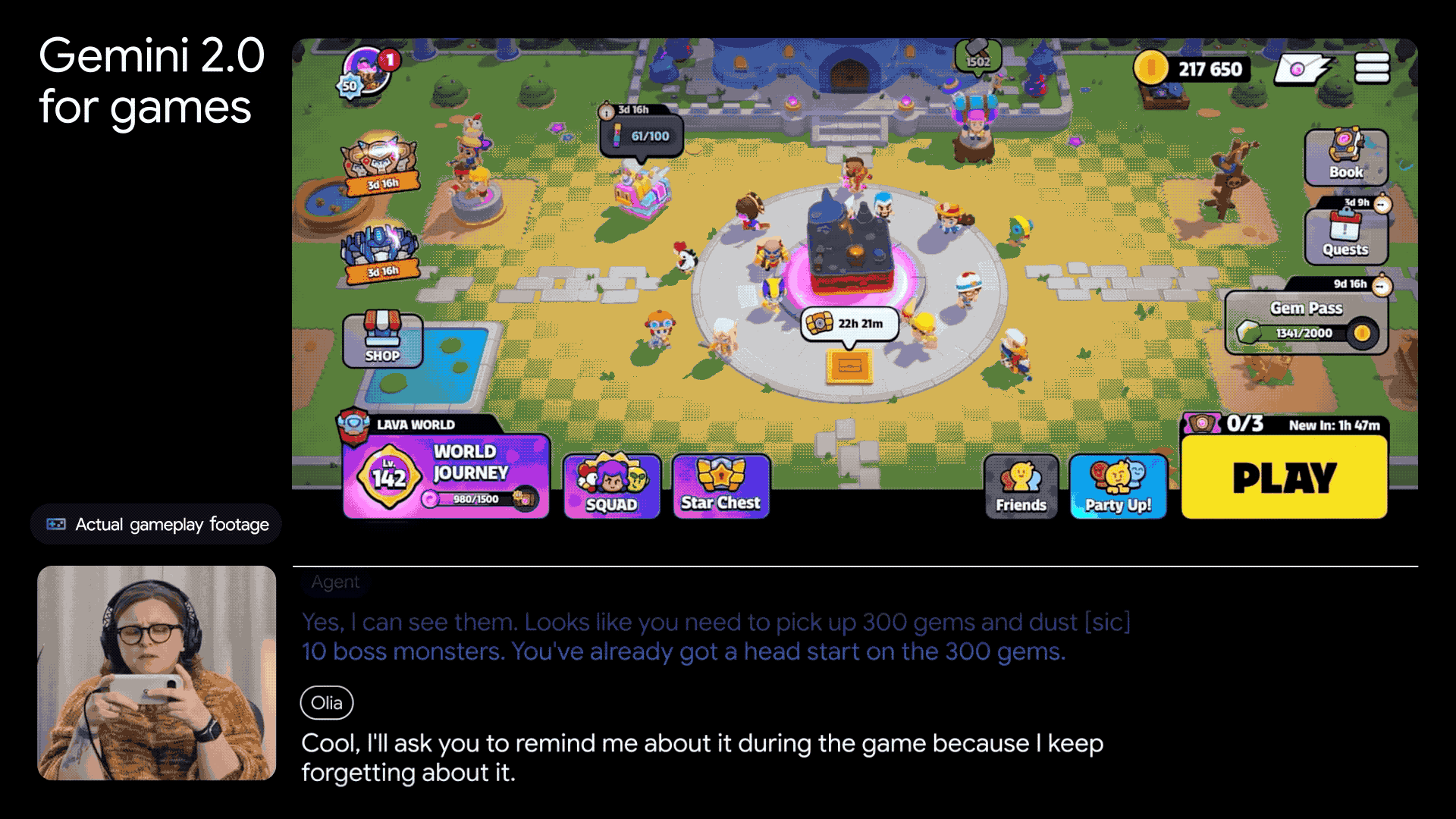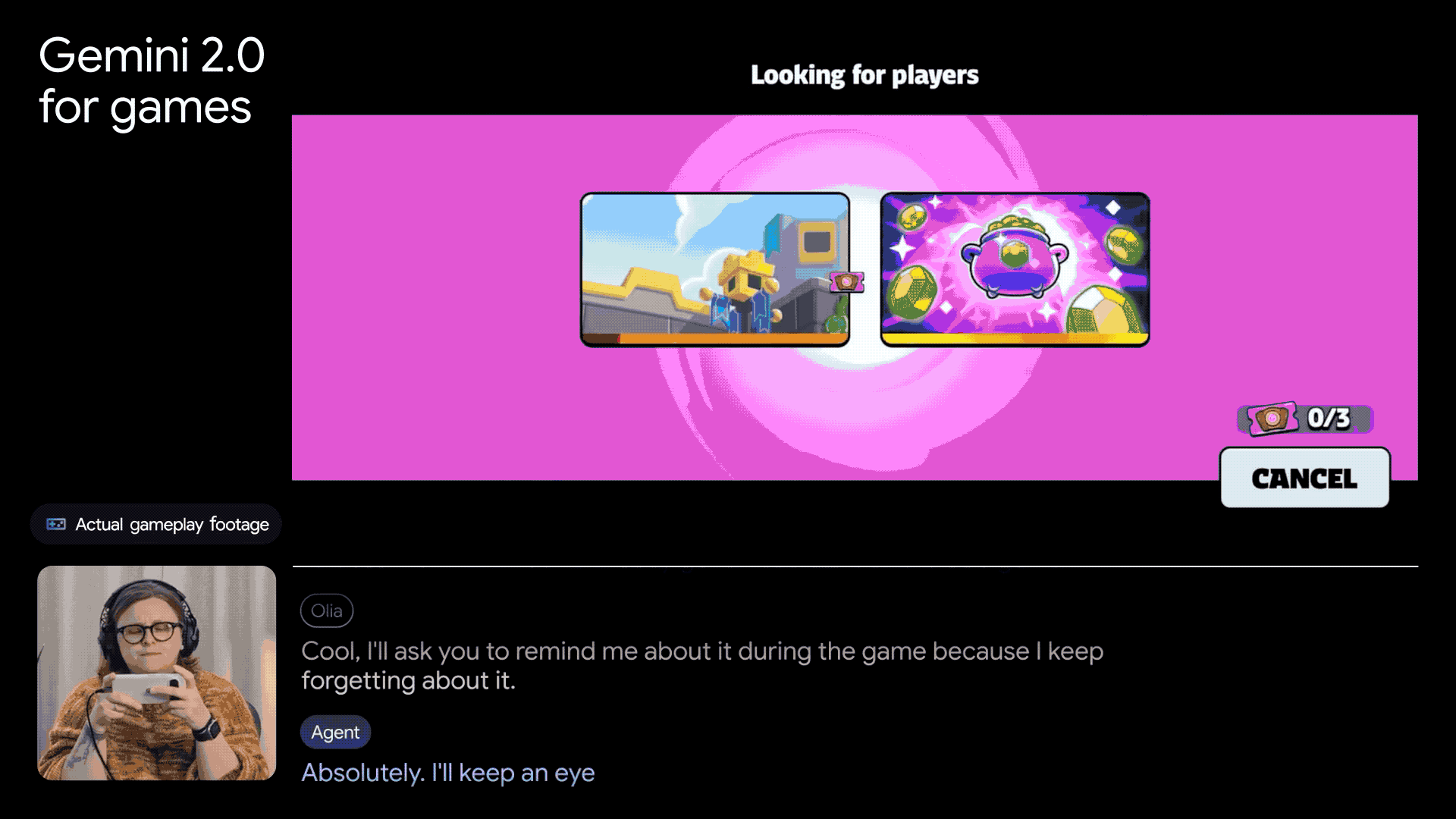
除了Gemini 2.0的发布,谷歌还宣布了最新量子芯片Willow的推出。谷歌首席执行官孙达尔·皮柴称其为迈向打造实用量子计算机的重要一步。Willow在扩展量子比特数量、减少错误以及提高性能方面取得了显著成就,为解决量子纠错领域的难题提供了新的思路。